

| 41. 아래를 참고할 때 시간별 사용량 테이블을 기반으로 고객별 사용금액을 출력하는 SQL로 가장 적절한 것은? |
 |
⓵ ⓶  ⓷  ⓸  |

** FROM 절을 제외하고 모두 같기 때문에 FROM 절만 보고 답을 고르면 된다!
-> INNER JOIN 구문을 묻는 문제임을 알 수 있다.
⓵
INNER JOIN 시간대구간 C ON (B.사용시간대 <= C.시작시간대 AND B.사용시간대 >= C.종료시간대)
예를 들어, B.사용시간대가 15:00인 경우 시간대구간 C에서는 12:00~16:00에 들어갈 수 있다.
'C.종료시간대 ≤ B.사용시간대 ≤ C.시작시간대' 라고 볼 수 있는데 '16:00 ≤ 15:00 ≤ 12:00' 는 맞지 않는 표현식이다.
= 오류
⓶
INNER JOIN 시간대별사용량 B
INNER JOIN 시간대구간 C ON (A.고객ID = B.고객ID AND B.사용시간대 BETWEEN C.시작시간대 AND C.종료시간대)INNER JOIN ~ ON ~ INNER JOIN ~ ON ~ : 하나의 JOIN에 ON으로 조건을 꼭 붙여줘야 한다.
= INNER JOIN 구문 오류
⓷
INNER JOIN 시간대별사용량 B ON (A.고객ID = B.고객ID)
INNER JOIN 시간대구간 C ON B.사용시간대 BETWEEN C.시작시간대 AND C.종료시간대고객 A와 시간대별사용량 B를 고객ID 컬럼으로 연결
시간대별사용량 B와 시간대구간 C을 조인하여, B.사용시간대가 C.시작시간대와 C.종료시간대 구간에 포함되는 행 추출
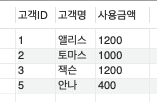
⓸
INNER JOIN 시간대별사용량 B ON (A.고객ID = B.고객ID)
BETWEEN JOIN 시간대구간 CBETWEEN JOIN 구문은 존재하지 않음!
| 42. 실행 결과가 다른 하나는? |
| ⓵ SELECT T.REGION_NAME, T.TEAM_NAME, T.STADIUM_ID, S.STADIUM_NAME FROM TEAM T INNER JOIN STADIUM S USING (T.STADIUM_ID = S.STADIUM_ID); ⓶ SELECT TEAM.REGION_NAME, TEAM.TEAM_NAME, TEAM.STADIUM_ID, STADIUM.STADIUM_NAME FROM TEAM INNER JOIN STADIUM ON (TEAM.STADIUM_ID = STATIDUM.STADIUM_ID) ⓷ SELECT T.REGION_NAME, T.TEAM_NAME, T.STADIUM_ID, S.STADIUM_NAME FROM TEAM T, STADIUM S WHERE T.STADIUM_ID = S.STADIRUM_ID ⓸ SELECT TEAM.REGION_NAME, TEAM.TEAM_NAME, TEAM.STADIUM_ID, STADIUM.STADIUM_NAME FROM TEAM, STADIUM WHERE TEAM.STADIUM_ID = STADIUM.STADIUM_ID |
USING절 : 두 테이블의 컬럼명이 같을 경우 조인 조건을 길게 적지않고 간단히 적을 수 있도록 하는 역할
-> ON절과 비슷하다고 볼 수 있다.
-> 반드시 괄호 안에 사용
**WHERE절**
SELECT e.ename, d.deptno
FROM emp e, dept d
WHERE e.deptno = d.deptno;
**JOIN~ON절**
SELECT e.ename, d.deptno
FROM emp e JOIN dept d ON (e.deptno = d.deptno);
**USING절**
SELECT e.ename, d.deptno
FROM emp e JOIN dept d USING(deptno);
위의 where, join~on, using 예시는 모두 같은 결과를 도출해낸다.
= ⓵은 오류
| 43. 아래 두 SQL이 같은 결과를 출력할 때, 빈칸 ㉠에 들어갈 내용으로 가장 적절한 것은? |
| [SQL(1)] SELECT ENAME, DNAME FROM EMP, DEPT ORDER BY ENAME; [SQL(2)] SELECT ENAME, DNAME FROM EMP ㉠ DEPT ORDER BY ENAME; |
| ⓵ FULL OUTER JOIN ⓶ SELF JOIN ⓷ NATURAL JOIN ⓸ CROSS JOIN |
FULL OUTER JOIN : 두 테이블 모두에서 일치하는 행과 일치하지 않는 행을 모두 포함하여 결과 반환
-> 일치하지 않는 행에는 NULL 값으로 반환하여 출력
--example
SELECT *
FROM emp e
FULL OUTER JOIN dept d ON e.deptno = d.deptno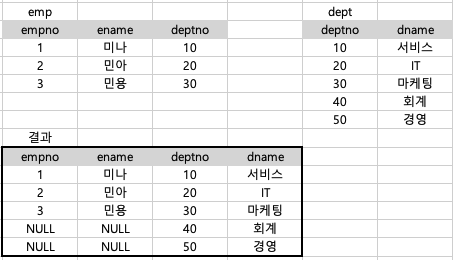
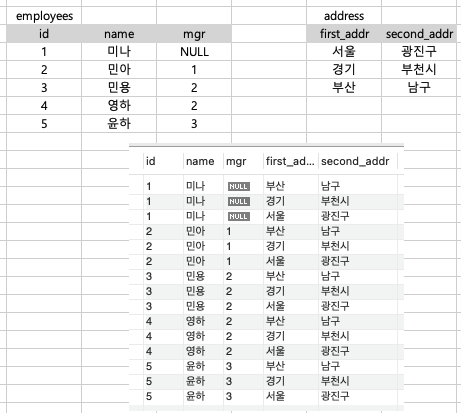
SELF JOIN : JOIN의 대상이 자기 자신
-> 같은 테이블이 두번 나오기 때문에 꼭 alias(별칭)을 지정해줘야 한다.
---1
SELECT e1.name AS Employee, e2.name AS Manager
FROM employees e1
LEFT JOIN employees e2 ON e1.mgr = e2.id;
---2
SELECT e1.name AS Employee, e2.name AS Manager
FROM employees e1
INNER JOIN employees e2 ON e1.mgr = e2.id;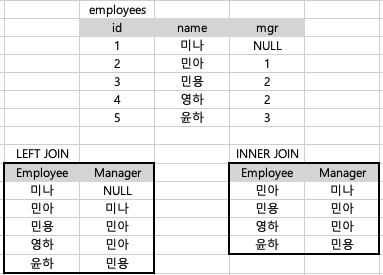
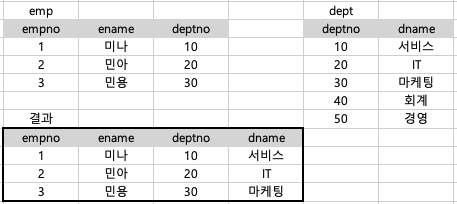
NATURAL JOIN : 두 테이블 간의 공통된 컬럼을 자동으로 찾아서 조인
-> 공통된 컬럼을 자동으로 찾기 때문에 ON절은 필요로 하지 않음
--example
SELECT *
FROM emp e
NATURAL JOIN dept dINNER JOIN과 비슷하다고 생각할 수 있다.
하지만, INNER JOIN의 경우 ON으로 조건을 명시해줘야 하고,
NATURAL JOIN은 공통된 컬럼을 자동으로 찾기 때문에 ON으로 조건을 명시해주지 않아도 된다.
CROSS JOIN : 한쪽 테이블의 모든 행과 다른 쪾 테이블의 모든 행을 조인시키는 기능
-> 전체 행 개수 : 두 테이블의 각 행의 개수를 곱한 수만큼 (M × N)
-- 명시적 CROSS JOIN 표현
SELECT * FROM 테이블1
CROSS JOIN 테이블2
-- 암시적 CROSS JOIN 표현
SELECT * FROM 테이블1, 테이블21) CROSS JOIN 이라고 명시를 해 주거나
2) 테이블 두 개를 콤마(,)로 걸어주고 조건절에 따로 명시하지 않으면 CROSS JOIN이 생성된다.
| 44. 아래를 참고할 때 SQL 실행 결과로 가장 적절한 것은? |
 [SQL] SELECT A.고객번호, A.고객명, B.단말기ID, B.단말기명, C.OSID, C.OS명 FROM 고객 A LEFT OUTER JOIN 단말기 B ON (A.고객번호 IN (11000, 12000) AND A.단말기ID = B.단말기ID) LEFT OUTER JOIN OS C ON (B.OSID = C.OSID) ORDER BY A.고객번호; |
⓵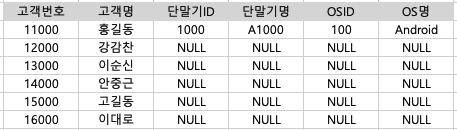 ⓶  ⓷  ⓸  |
| FROM 고객 A LEFT OUTER JOIN 단말기 B ON (A.고객번호 IN (11000, 12000) AND A.단말기ID = B.단말기ID) LEFT OUTER JOIN OS C ON (B.OSID = C.OSID) | 고객 A와 단말기 B를 단말기ID 컬럼으로 연결하고, A.고객번호가 11000 또는 12000인 컬럼 추출 ** 고객 A가 기준 ** -> 고객 A 컬럼은 모두 출력, 조건에 맞지 않는 행은 NULL로 출력 단말기 B와 OS C를 OSID 컬럼으로 연결 ** 단말기 B가 기준 ** |
 | |
| SELECT A.고객번호, A.고객명, B.단말기ID, B.단말기명, C.OSID, C.OS명 | 위 조건에 만족하는 행 출력 |
| ORDER BY A.고객번호 | A.고객번호 기준으로 오름차순 정렬 (ASC는 생략 가능) |
| 45. 아래 SQL에서 실행 결과가 같은 것은? |
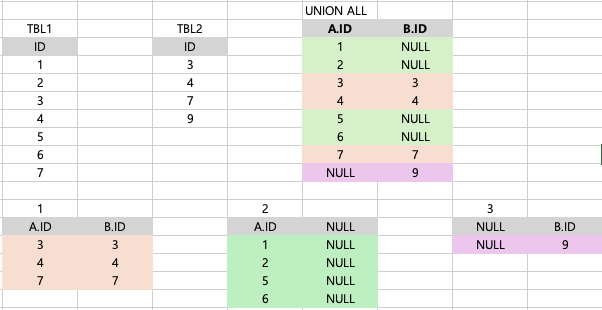
| (가) SELECT A.ID, B.ID FROM TBL1 A FULL OUTER JOIN TBL2 B ON A.ID = B.ID (나) SELECT A.ID, B.ID FROM TBL1 A LEFT OUTER JOIN TBL2 B ON A.ID = B.ID UNION SELECT A.ID, B.ID FROM TBL1 A RIGHT OUTER JOIN TBL2 B ON A.ID = B.ID (다) SELECT A.ID, B.ID FROM TBL1 A, TBL2 B WHERE A.ID = B.ID UNION ALL SELECT A.ID, NULL FROM TBL1 A WHERE NOT EXISTS (SELECT 1 FROM TBL2 B WHERE A.ID = B.ID) UNION ALL SELECT NULL, B.ID FROM TBL2 B WHERE NOT EXISTS (SELECT 1 FROM TBL1 A WHERE B.ID = A.ID) |
| ⓵ (가), (나) ⓶ (가), (다) ⓷ (나), (다) ⓸ (가), (나), (다) |
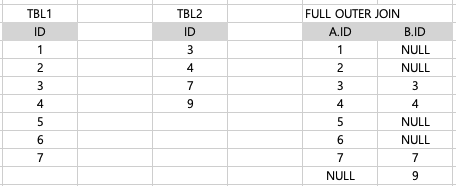
(가)
SELECT A.ID, B.ID
FROM TBL1 A
FULL OUTER JOIN TBL2 B ON A.ID = B.IDTBL1 A와 TBL2 B를 ID컬럼을 기준으로 FULL OUTER JOIN
-> 두 테이블 모두에서 일치하는 행과 일치하지 않는 행을 모두 포함하여 결과 반환
-> 일치하지 않는 행에는 NULL 값으로 반환하여 출력
(나)
SELECT A.ID, B.ID
FROM TBL1 A
LEFT OUTER JOIN TBL2 B ON A.ID = B.ID
UNION
SELECT A.ID, B.ID
FROM TBL1 A
RIGHT OUTER JOIN TBL2 B ON A.ID = B.IDOUTER JOIN : 열을 추가하여 JOIN
UNION : 행을 추가하여 각 쿼리의 결과를 반환하는 합집합 (중복제거)
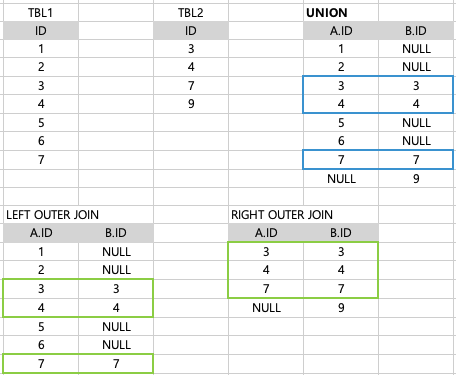
초록색 부분은 중복되었지만 UNION 한 결과를 보면 중복이 제거되어 나온 것을 알 수 있다.
두 개의 쿼리의 합집합으로 결과가 출력된다.
(다)
--1
SELECT A.ID, B.ID
FROM TBL1 A, TBL2 B
WHERE A.ID = B.ID
--2
UNION ALL
SELECT A.ID, NULL
FROM TBL1 A
WHERE NOT EXISTS (SELECT 1 FROM TBL2 B WHERE A.ID = B.ID)
--3
UNION ALL
SELECT NULL, B.ID
FROM TBL2 B
WHERE NOT EXISTS (SELECT 1 FROM TBL1 A WHERE B.ID = A.ID)UNION ALL : 행을 추가하여 각 쿼리의 모든 결과를 합집합 (중복제거 안함)
| NOT EXISTS (SELECT 1 FROM TBL2 B WHERE A.ID = B.ID) | A.ID가 TBL2에 존재하는지 검사하는 서브쿼리 -> 존재하면 FALSE (A.ID = B.ID 제외하고 나머지 출력) -> 존재하지 않으면 TRUE (A.ID 그대로 출력) |
| NOT EXISTS (SELECT 1 FROM TBL1 B WHERE B.ID = A.ID) | B.ID가 TBL1에 존재하는지 검사하는 서브쿼리 -> 존재하면 FALSE (B.ID = A.ID 제외하고 나머지 출력) -> 존재하지 않으면 TRUE (A.ID 그대로 출력) |
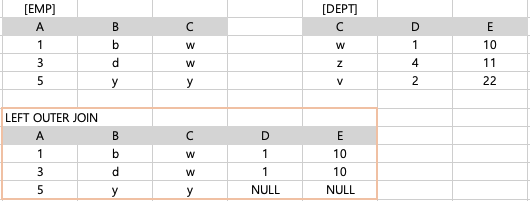
| 46. 아래에서 EMP 테이블과 DEPT 테이블을 LEFT, FULL, RIGHT 외부조인(OUTER JOIN) 하면 생성되는 결과 건수로 가장 적절한 것은? |
 |
| ⓵ 3건, 5건, 4건 ⓶ 4건, 5건, 3건 ⓷ 3건, 4건, 4건 ⓸ 3건, 4건, 5건 |
1)
emp e LEFT OUTER JOIN dept d ON e.C = d.C(LEFT) EMP 테이블 전체 + 해당하는 조건에 맞는 DEPT 테이블의 행
-> 조건에 맞지 않는 행은 NULL 값으로 반환하여 출력
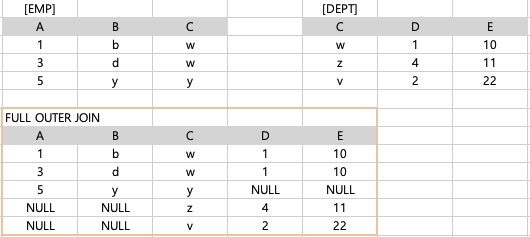
2)
emp e FULL OUTER JOIN dept d ON e.C = d.C두 테이블 모두에서 일치하는 행과 일치하지 않는 행을 모두 포함하여 결과 반환
-> 일치하지 않는 행에는 NULL 값으로 반환하여 출력
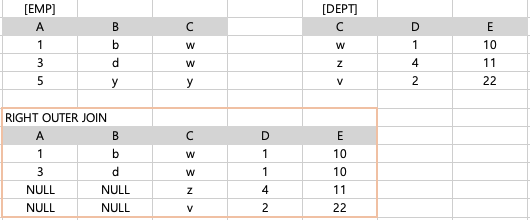
3)
emp e RIGHT OUTER JOIN dept d ON e.C = d.C(RIGHT) DEPT 테이블 전체 + 해당하는 조건에 맞는 EMP 테이블의 행
-> 조건에 맞지 않는 행은 NULL 값으로 반환하여 출력
| 47. DEPT와 EMP를 조인하되 사원이 없는 부서 정보도 같이 출력하고자 할 때, 아래 SQL의 빈칸 ㉠에 들어갈 내용으로 가장 적절한 것은? |
| SELECT E.ENAME, D.DEPTNO, D.DNAME FROM DEPT D ㉠ EMP E ON D.DEPTNO = E.DEPTNO; |
| ⓵ LEFT OUTER JOIN ⓶ RIGHT OUTER JOIN ⓷ FULL OUTER JOIN ⓸ INNER JOIN |
- 사원이 없는 부서정보 -> 사원의 값은 NULL, 부서정보의 값은 있다는 의미로 볼 수 있다.
- DEPT 테이블 : 부서정보를 담고 있는 테이블
- EMP 테이블 : 사원정보를 담고 있는 테이블
--> EMP E 의 값은 NULL을 가지고, DEPT D 의 값은 NULL을 가지지 않으려면 DEPT 테이블을 기준으로 OUTER JOIN
= LEFT OUTER JOIN
| 48. 아래 SQL의 실행 결과로 가장 적절한 것은? |
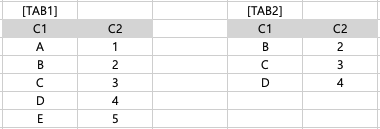 [SQL] SELECT * FROM TAB1 A LEFT OUTER JOIN TAB2 B ON (A.C1 = B.C1 AND B.C2 BETWEEN 1 AND 3) |
⓵ ⓶  ⓷  ⓸  |
SELECT *
FROM TAB1 A
LEFT OUTER JOIN TAB2 B ON (A.C1 = B.C1 AND B.C2 BETWEEN 1 AND 3)- FROM : TAB1 전체 테이블을 가져오고, TAB1 테이블과 TAB2 테이블은 C1 컬럼으로 연결
- 조건: B.C2의 값이 1과 3 사이어야한다.
- SELECT : TAB1 컬럼 전체와 TAB2 컬럼 전체를 가져온다.
- A.C1, A.C2, B.C1, B.C2
| 49. 아래의 오라클 SQL을 동일한 결과를 출력하는 ANSI 표준 구문으로 변경하고자 할 때 가장 적절한 SQL은? |
 [SQL] SELECT A.게시판ID, A.게시판명, COUNT(B.게시글ID) AS CNT FROM 게시판 A, 게시글 B WHERE A.게시판ID = B.게시판ID(+) AND B.삭제여부(+) = 'N' AND A.사용여부 = 'Y' GROUP BY A.게시판ID, A.게시판명 ORDER BY A.게시판ID; |
⓵ ⓶  ⓷  ⓸  |
- (+) = : 해당 기호를 한 테이블에서 조건의 데이터가 없다면 NULL을 사용하라!
- ex) WHERE emp.dept_id = dept.dept_id(+)
: dept 테이블에서 dept_id가 emp 테이블의 dept_id 와 일치하는 것이 없다면 NULL을 사용하라
=> 즉, emp LEFT OUTER JOIN dept 와 같다는 것을 알 수 있다. - (+) 기호의 반대편 테이블은 전체 출력 되는 것!
- ex) WHERE emp.dept_id = dept.dept_id(+)

| FROM 게시판 A, 게시글 B | 게시판 테이블의 별칭 A, 게시글 테이블의 별칭 B로 하고, A 테이블과 B 테이블을 가져온다. |
| WHERE A.게시판ID = B.게시판ID(+) AND B.삭제여부(+) = 'N' AND A.사용여부 = 'Y' | <조건> 게시글 B의 게시판ID가 게시판 A의 게시판ID와 일치하는 것이 없다면 NULL 출력 -> 게시판 테이블 A 전체 출력 -> 게시판 A LEFT OUTER JOIN 게시글 B 게시글 B의 삭제여부가 N 게시글 B의 삭제여부가 N과 일치하지 않다면 B.삭제여부를 NULL로 출력 게시판 A의 사용여부가 Y |
 | |
| GROUP BY A.게시판ID, A.게시판명 | 게시판 A의 게시판ID와 게시판 A의 게시판명을 기준으로 그룹화 |
| SELECT A.게시판ID, A.게시판명, COUNT(B.게시글ID) AS CNT | 게시판 A의 게시판ID, 게시판명 게시글 B의 게시글ID의 NULL을 제외한 행의 수 (별칭: CNT) |
| ORDER BY A.게시판ID | 게시판 A의 게시판ID를 기준으로 오름차순 정렬 |
 | |
- 우선 문제의 SQL은 게시판 A LEFT OUTER JOIN 게시글 B 임을 알 수 있다.
=> ⓸ 제외 (게시판 A RIGHT OUTER JOIN 게시글 B 이기 때문에) - A.게시판ID = B.게시판ID(+) AND B.삭제여부(+) = 'N'
-> B의 게시판ID와 삭제여부는 값이 일치하지 않다면 NULL을 출력하는 것을 보아 해당 조건은 LEFT OUTER JOIN의 ON절에 해당하는 것을 알 수 있다. - 결과적으로 FROM절과 WHERE절을 정리하면
FROM절 - 게시판 A LEFT OUTER JOIN 게시글 B ON (A.게시판ID = B.게시판ID AND B.삭제여부 = 'N')
WHERE절 - A.사용여부 = 'Y'
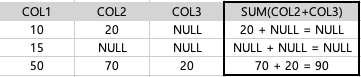
| 50. 아래에 대한 설명으로 가장 적절한 것은? (단, 칼럼의 타입은 NUMBER 이다.) |
 |
| ⓵ SELECT SUM(COL2) FROM TAB1 의 결과는 NULL이다. ⓶ SELECT SUM(COL1 + COL2 + COL3) FROM TAB1 의 결과는 185이다. ⓷ SELECT SUM(COL2 + COL3) FROM TAB1 의 결과는 90이다. ⓸ SELECT SUM(COL2) + SUM(COL3) FROM TBA1 의 결과는 90이다. |
**SUM( ) 함수**
: NULL값을 제외하고 계산
SUM( ) 함수의 괄호 안에 연산자가 있다면 따로 컬럼을 빼주어 연산해주는 것이 헷갈리지 않게 연산할 수 있다.
-> 보통 SUM( )을 하면 세로로(컬럼) 연산하기 때문에 (이해를 더 쉽게 하기 위해서)
| SUM(COL2) | NULL값을 제외하고 20+70=90 | SUM(COL3) | NULL값을 제외하고 20 |
 | 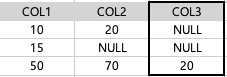 | ||
| SUM(COL2 + COL3) | NULL 값을 제외하고 90 | SUM(COL1 + COL2 + COL3) | NULL값을 제외하고 140 |
 |  | ||
| 51. 아래에서 설명하는 서브쿼리의 종류로 가장 적절한 것은? |
| 서브쿼리의 실행 결과로 여러 칼럼을 반환한다. 메인쿼리의 조건절에 여러 칼럼을 동시에 비교할 수 있다. 서브쿼리와 메인쿼리에서 비교하고자 하는 칼럼 개수와 칼럼의 위치가 동일해야 한다. |
| ⓵ 단일 행(Single Row) 서브쿼리 ⓶ 다중 칼럼(Multi Column) 서브쿼리 ⓷ 다중 행(Multi Row) 서브쿼리 ⓸ 단일 칼럼(Single Column) 서브쿼리 |
- 서브쿼리 : 메인 쿼리 내에서 다른 쿼리를 포함하여 실행하는 쿼리
- 반환 값에 따른 서브쿼리
- 단일 행 서브쿼리 : 서브쿼리 결과 = 단일 행
-> 단일 행 비교연산자 (=, <, >, <=, >=, <>) - 다중 행 서브쿼리 : 서브쿼리 결과 = 여러 행
-> 다중 행 비교연산자 (IN, ALL, ANY, SOME, EXISTS) - 다중 칼럼 서브쿼리 : 서비쿼리 결과 = 여러 칼럼
-> 메인쿼리의 조건절에 여러 칼럼을 동시에 비교 가능
-> 비교하고자 하는 칼럼 개수와 칼럼의 위치가 동일해야 함
- 단일 행 서브쿼리 : 서브쿼리 결과 = 단일 행
- 위치에 따른 서브쿼리
- 스칼라 서브쿼리 : SELECT절에 위치. 단일 값을 반환하는 서브쿼리
-> 단일 행, 단일 칼럼 반환 - 인라인 뷰 : FROM절에 위치하는 서브쿼리
- 상관 서브쿼리 : WHERE절에 위치. 주 쿼리의 칼럼을 참조하는 서브쿼리
-> 단일 행, 다중 행 반환
- 스칼라 서브쿼리 : SELECT절에 위치. 단일 값을 반환하는 서브쿼리
- 반환 값에 따른 서브쿼리
| 52. SQL 실행 결과가 다른 하나는? |
| ⓵ SELECT COL1, SUM(COL2) FROM T1 GROUP BY COL1 UNION ALL SELECT NULL, SUM(COL2) FROM T1 ORDER BY 1 ASC; ⓶ SELECT COL1, SUM(COL2) FROM T1 GROUP BY GROUPING SETS (COL1) ORDER BY 1 ASC; ⓷ SELECT COL1, SUM(COL2) FROM T1 GROUP BY ROLLUP(COL1) ORDER BY 1 ASC; ⓸ SELECT COL1, SUM(COL2) FROM T1 GROUP BY CUBE(COL1) ORDER BY 1 ASC; |
- ROLLUP( ) : 그룹별 소계와 총계를 같이 계산, 기준 필드가 여러 개인 경우 콤마로 구분
- 기준 필드가 2개일 때: 1차 기준 필드에 대한 소계를 계산 + 총계
- CUBE( ) : 모든 기준 필드에 대한 소계
- 기준 필드가 2개일 때 : 1차 기준 필드에 대한 소계를 계산 + 2차 기준 필드에 대한 소계 + 총계
- GROUPING SET( ) : 그룹별 소계만 계산
- 기준 필드가 2개일 때 : 1차 기준 필드에 대한 소계 + 2차 기준 필드에 대한 소계
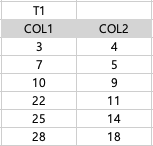
| ⓵ SELECT COL1, SUM(COL2) FROM T1 GROUP BY COL1 | T1 테이블을 가져오고, COL1 값을 기준으로 그룹화한 후 COL1 과 SUM(COL2)를 가져온다. |
 | |
| SELECT NULL, SUM(COL2) FROM T1 | T1 테이블을 가져오고, NULL값과 SUM(COL2)값을 가져온다. |
 | |
| 위의 결과를 "UNION ALL"한 후 값은 "ORDER BY 1 ASC"한 값은? | |
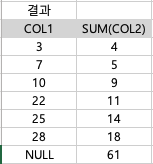 -> UNION ALL과 UNION의 차이: - UNION: 중복되는 값은 제거하여 결과 합집합 (DISTINCT) - UNION ALL: 중복되는 값 모두 포함하여 결과 합집합 (DISTINCT 하지 않음) | |
| ⓶ SELECT COL1, SUM(COL2) FROM T1 GROUP BY GROUPING SETS (COL1) ORDER BY 1 ASC; | T1 테이블을 가져오고 COL1을 기준으로 소계를 낸다. COL1과 SUM(COL2)의 값을 가져오고 COL1을 기준으로 오름차순 정렬한다. |
 -> GROUPING SET과 CUBE, ROLLUP의 차이: - GROUPING SET: 지정 필드에 대한 소계만 낸다. - CUBE, ROLLUP: 지정 필드에 대한 소계와 총계를 같이 낸다. | |
'자격증' 카테고리의 다른 글
| 리눅스마스터 오답노트 3️⃣ (0) | 2024.09.04 |
|---|---|
| 리눅스마스터 오답노트 2️⃣ (3) | 2024.09.03 |
| 리눅스마스터 오답노트 1️⃣ (1) | 2024.09.03 |
| SQLD 기출문제 2과목(21~40) 오답정리 (4) | 2024.08.11 |
| SQLD 기출문제 2과목(1~20) 오답정리 (0) | 2024.08.08 |